


 Documentation
Documentation
Flow Control
Introduction
Based on the runtime statistics collected in previous slots, FlowSlot will use pre-set rules to decide whether the incoming requests should be controlled.
SphU.entry(resourceName) will throw FlowException if any rule is triggered. You can customize your own logic by catching this exception.
One resource can have multiple flow control rules. FlowSlot traverses these rules until one of them is triggered or all rules have been passed.
A flow control rule consists of the following elements, and you can use a combination of different elements to cater for different flow control needs.
- resource:resource name
- count: thresholds of flow control
- grade: threshold type, can be QPS or thread number
- strategy: select flow control strategy based on calling trace (invocation chain)
- controlBehavior: effect of traffic shaping
Flow Control by Thread/QPS
Metric Type
You can control either by thread count or QPS. It is defined by the grade field in FlowRule. Both concurrent thread count and request count are collected at runtime, and you can run the following command to view the statistics:
curl http//localhost:8719/tree?type=root
The output is as follows:
idx id thread pass blocked success total aRt 1m-pass 1m-block 1m-all exception
2 abc647 0 460 46 46 1 27 630 276 897 0
- thread: the number of threads which are currently processing the resource;
- pass: the count of incoming requests within one second;
- blocked: the count of requests blocked within one second;
- success: the count of the requests successfully processed within one second;
- RT: the average response time of the requests within a second;
- total: the sum of incoming requests and blocked requests within one second;
- 1m-pass: the count of incoming requests within one minute;
- 1m-block: the count of requests blocked within one minute;
- 1m-all: the total of incoming and blocked requests within 1 minute;
- exception: the count of exceptions in one second.
Concurrent Thread count
This mode is usually used to protect threads from being occupied. If a resource takes a long time to finish, threads blocked in this resource will begin to be occupied. The longer the response takes, the more threads might be occupied.
Besides thread count, there are 2 other ways to achieve this, thread pool or semaphore.
- Thread pool: Allocate a thread pool to handle these resources. When there is no more idle thread in the pool, the request is rejected without affecting other resources.
- Semaphore: Use semaphore to control the concurrent count of the threads.
The benefit of using thread pools is that you can isolate business logic completely by pre-allocating thread pools. But it also brings us extra costs of context switch and additional threads. If the incoming request is already handled in a separated thread, for instance, a servlet request, it will almost double the thread count if using the thread pool mode.
So we recommend to use concurrent thread count flow control, which represents lightweight semaphore isolation.
QPS
When QPS exceeds the threshold, we will take actions to control the incoming requests, and this can be done by configuring the controlBehavior field in FlowRule.
1. Immediately reject (RuleConstant.CONTROL_BEHAVIOR_DEFAULT)
This is the default behavior. The exceeded requests are rejected immediately and the FlowException is thrown.
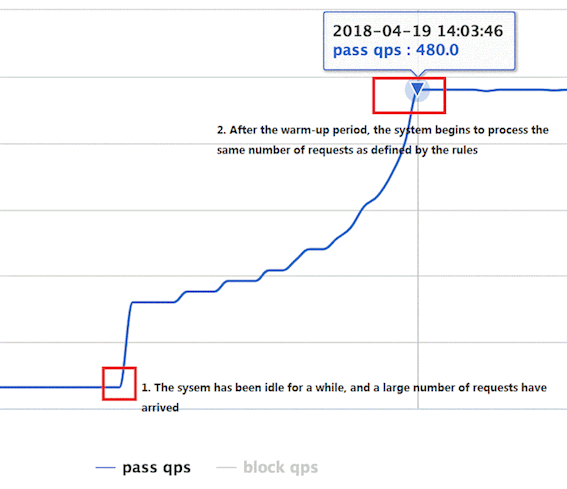
2. WarmUp(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)
If the usage of the system has been low for a while, but all of a sudden a large amount of requests comes in, the system might not be able to handle all these requests at once. However, if we steadily increase the incoming requests and allows the system to warm up, it may be able to handle all the requests eventually.
This warm-up period can be configured by setting the warmUpPeriodSec field in FlowRule.
3.Rate limiter (RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)
This strategy strictly controls the interval between requests. In other words, it allows requests to pass at a uniform rate.

This strategy is an implement of leaky bucket. It is used to handle requests at a stable rate and is often used to process burst requests instead of rejecting them. For instance, a sudden inflow of messages. When a large number of requests arrive at the same time, the system can handle all these incoming requests at a fixed rate.
Flow Control by Call Path
We use the NodeSelectorSlot to establish the paths of resources, and the ClusterNodeBuilderSlot to collect the caller's runtime data.
By caller
When calling ContextUtil.enter(resourceName, origin), the parameter origin indicates the identity of the caller. ClusetNodeBuilderSlot will collect this info, and uses it to perform flow control.
This information can be displayed by the following command:
id: nodeA
idx origin threadNum passedQps blockedQps totalQps aRt 1m-passed 1m-blocked 1m-total
1 caller1 0 0 0 0 0 0 0 0
2 caller2 0 0 0 0 0 0 0 0
The origin can be defined by the field limitApp in FlowRule. This field has the following values:
default: No specific caller. If the total value of this resource exceeds the threshold defined in this rule, the incoming request will be blocked.<<origin>>: A specific caller has exceeded the threshold defined in the rule.other: This rule applies to requests from a caller that is not defined explicitly in theoriginfield for this resource.
By entrance
The path is maintained in NodeSelectorSlot. For example, the resource nodes can come from either entrance1 or entrance2.
machine-root
/ \
/ \
Entrance1 Entrance2
/ \
/ \
DefaultNode(nodeA) DefaultNode(nodeA)
We can shape the flow by setting the field strategy to RuleConstant.CHAIN, and ref_identity to a specified entrance.
By related resource
For instance, two resources will access the same database record. ResourceA will read records from the database, resourceB will write records to the database. The frequency of ResourceA accessing the database depends on ResourceB. We can achieve this by configuring a rule for ResourceA with the value of the strategy field as RuleConstant.RELATE, and the value of ref_identity as ResourceB.